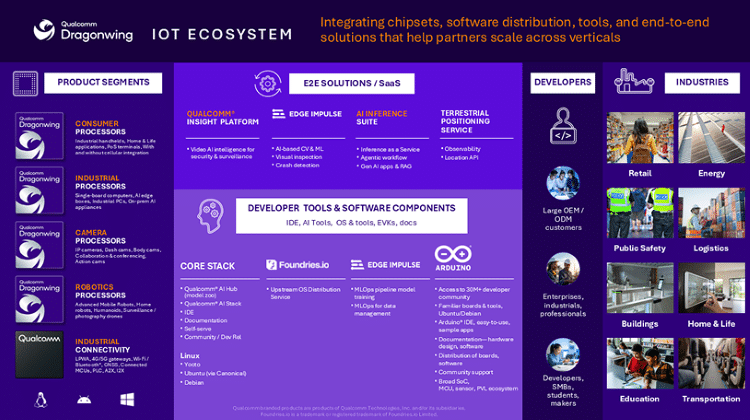
數據隱私/模型偏見現風險 GAI聯邦學習助資料治理
生成式人工智慧(GAI)的快速發展是雙面刃,為產業帶來亮眼的應用進展,然而假資訊、模型偏見與資料管理等風險也隨之出現。面對AI生成的惡意內容,用生成式AI偵測與防範,可有效辨別假資料。在模型訓練方面,來自不同國家的訓練資料會造成模型偏見,因此各國開始發展主權模型,訓練符合當地需求的生成式AI。另一方面,聯邦學習技術的發展,確保訓練資料保留在擁有者手上,可望有效解決資料治理的挑戰。...
》想看更多內容?快來
【免費加入會員】或
【登入會員】,享受更多閱讀文章的權限喔!