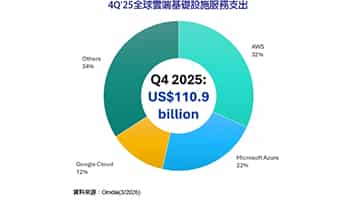
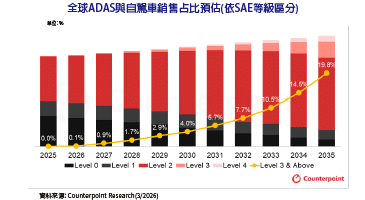
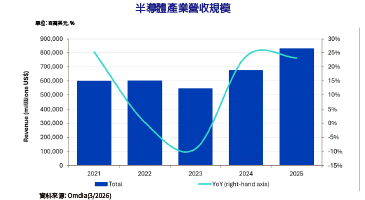
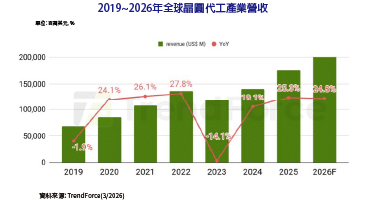
信任/安全成兩大核心課題 AI時代面臨新挑戰
人工智慧(AI)即將成為大多數數位基礎設施與應用中的核心要素,為其增添一層具附加價值的智慧能力。隨著這種趨勢,AI將在自動化複雜任務與支援關鍵決策方面扮演越來越重要的角色。因此,解決AI的安全與信任挑戰,是負責任地採用AI的關鍵前提。實際上,如果人類無法信任AI的運作方式,那麼這些系統就無法被廣泛採用。
AI系統屬於更廣義的數位系統範疇,這些系統必須具備強健的網路資安能力,才能達成穩定且可信賴的運作。然而,AI系統同時也帶來一系列獨特的安全與信任挑戰,包括:
結構與運作複雜:
與傳統軟體不同,AI模型本身非常複雜,且經常以「黑箱」方式運作,使其決策過程變得不透明。舉例來說,許多基於大型語言模型(例如ChatGPT)的應用,其輸出結果與資料推論過程,對使用者來說難以理解或解釋。這種缺乏透明度的特性,在醫療或自駕車等高風險應用場景中風險尤為顯著。此外,若使用者無法完全理解或審查AI系統,信任就無從建立,也因此成為推廣障礙。
資料保護問題:
AI系統仰賴龐大的資料庫進行訓練與操作,而這種高度依賴使其面臨資料外洩、未授權存取與資料投毒等安全風險。由於這些漏洞,惡意攻擊者可能操控訓練資料庫,以干擾或破壞AI輸出結果。因此,保障資料庫的完整性與安全性是一項極具挑戰的任務。
決策倫理疑慮:
許多AI系統因訓練資料本身存在偏見而產生偏頗的運作方式,導致不公平甚至歧視性結果。同時,AI所作決策往往缺乏問責機制,例如當自動化系統出錯時,究竟由誰負責尚不明確。這類問題可能導致公眾對AI科技的信任徹底崩潰。
鑑於上述挑戰,建立AI安全與信任的穩固框架是當務之急。這類框架應促進AI的可解釋性與可理解性,以提升透明度,同時應透過先進的加密技術與安全資料共享協議,確保資料安全。此外,更重要的是,要推動具備公平性、問責性與包容性等明確指引的倫理標準,以減少偏見並強化社會對AI的信心。這類框架的建立需要多方利害關係人共同參與,包括政策制定者、技術專家與產業領袖,一起制定能兼顧道德責任與創新推進的解決方案。
根據Arm...
》想看更多內容?快來
【免費加入會員】或
【登入會員】,享受更多閱讀文章的權限喔!