
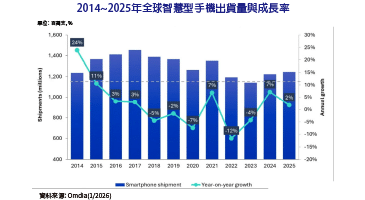
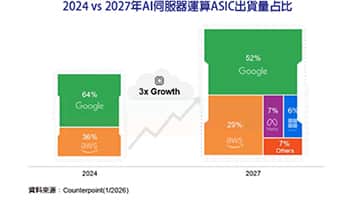
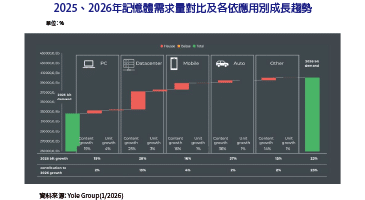
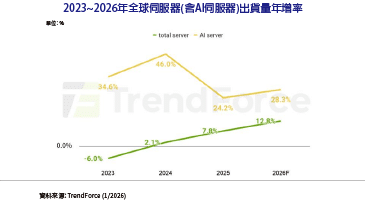





最近產業的典範轉移中,建立人工智慧(AI)系統可以從一般模型開始,透過使用自適應預先訓練模型,接著採用遷移學習(Transfer Learning)調整不同的下游任務,特別是透過Zero-shot、Few-shot、模型微調(Fine-tuning)和提示技術,都造就了規模不斷成長的Transformer模型。例如,GPT-3 175B、Gopher 280B和MT-NLG 530B等模型成長到數十億參數的規模。這些預訓練的語言模型在多種自然語言領域的任務中,實現了此領域內較先進的語言處理準確度。
廠商如Tachyum開發Prodigy處理器,以面對AI模型規模持續成長的趨勢。該處理器為了滿足爆炸性成長且更複雜的自然語言處理(NLP)需求,包括需要更複雜的NLP模型及更精準的對話式AI,透過採用低精度的數據類型,並且提供稀疏矩陣相乘(Sparse Matrix Multiplication)的指令,來壓縮深度學習模型。
量化是其中一種優化模型的技術,可有效減少神經網路模型占用的記憶體,以及神經網路訓練和推論的時間。量化的原理是減少神經網路中,數值的精度,包含權重(Weight)和網路內的運算。以Prodigy為例,其8位元浮點規格(FP8)具有1、5、2位元的符號(Sign)、指數(Exponent)、尾數(Mantissa)格式,並在這之中謹慎選擇格式來表示權重、特徵向量(Activation,或稱為Feature map)、誤差量和梯度(圖1)。16位元浮動規格(FP16)具有1、6、9格式,用於通用矩陣(GEMM)堆積。在對神經網路中的資料分布進行研究,特別是在ResNet18、ResNet101和SqueezeNet應用於Cifar100和ImageNet資料集,所得到的梯度統計結果,FP8和FP16格式都被選用。上述研究的目的,重點在於取得準確度和動態範圍的平衡。

基於Mixed Precision Training強化運算速度
AI領域已經廣泛研究如何降低精度,並且避免過度影響模型的表現。近期的研究方向,則大多聚焦在如何將降低精度的技術應用於推論階段。這表示執行推論所需的位元數,可以縮小到僅2~4個位元,且通常可以維持推論的準確度。
然而,降低資料精度來訓練DNN模型較為困難,因為需要確保模型在反向傳播(Back-propagation)過程的梯度不會失真。根據近期的研究結果顯示,在不影響模型準確度的前提下,訓練DNN模型至少需要16位元的精度。因此,市場上新推出的運算平台開始提供可支援16位元浮點訓練的硬體,並具備超過或等同於32位元系統的表現。
即便市場上的運算平台硬體支援以FP16為主流,FP8運算平台仍可以有效訓練DNN模型。為了充分利用8位元運算平台的優勢,不只是8位元的整數型態,廠商如Tachyum也採用8位元的浮點數型態,用於訓練DNN模型的前向及反向傳遞(Forward and Backward Pass)運算。然而降低精度的同時,仍保留模型準確度,需要克服幾項挑戰。首先,當所有用於GEMM和卷積運算的運算元,也就是權重、特徵向量、誤差和梯度減少到8位元時,大多數的DNN模型準確度會明顯下降。其次,將GEMM中堆積的位元精度從32位元降低到16位元,將明顯影響DNN模型訓練的收斂。
而Prodigy處理器允許使用者僅用FP8,來表示所有用於訓練DNN模型的矩陣及張量運算(Tensor Computation)。此外,在混合精度訓練的過程中,FP32 Master copy of weights可以下降到16位元,有助於在不影響模型收斂速度與準確度的前提下,進一步提升未來深度學習硬體平台的運算效率,同時降低功耗與記憶體頻寬需求。
逐層執行梯度縮放
為了避免在使用FP8量化梯度時可能出現下溢(Underflow),通常會在訓練中採用損失縮放。損失縮放有靜態與動態兩種形式。由於訓練過程中,梯度分布會出現變化,因此需要動態縮放。
選擇適合每一層的固定或動態全域損失縮放(Global Loss Scale)頗具挑戰性,並且可能最終發現無法進一步降低動態範圍內的FP精度。層與層之間的高度變化性(High Variability)導致選擇同一個全域損失縮放很不容易。因此,採用FP8數據類型來訓練DNN模型,需要逐層進行梯度縮放,而非使用全域損失縮放。
FP8量化方案
過去的研究在實驗中使用了兩種量化方案,包含Semi floating point 8(SFP8)及Floating point 8(FP8)兩種。SFP8只量化前向傳遞的部分,反向傳遞的數據則保留完整的32位元精度,而FP8則會量化前向與反向傳遞的數據(圖2)。

當SFP8運算前向傳遞數據的結果,輸入的數據及參數會量化為全域。為了有效運用較低的動態範圍,必須先透過縮放函數(Scaling Function),將輸入和參數進行縮放。例如,參數可以是除以最大值之後的結果。然後量化的變數會用於FP8矩陣乘法運算元,且運算結果會重新調整回原本的動態範圍。更新反向傳遞的參數時,梯度則會以完整的精度(FP32)來使用,量化的變化量將被縮放還原。梯度和參數的比值,以及梯度和輸入的比值,能被正確的匹配,進而保持準確度。
FP8的運算結果與SFP8相同,更新後的參數基於重新縮放、量化的輸出梯度和量化的變化量(包含數據輸入與參數)運算。這邊的梯度相較於參數和輸入數據,是接連著按比例縮小,再次回到完整的精度。
關於訓練時相關的超參數,所有模型都使用AdamW最佳化器和Cosine scheduler進行熱啟動訓練。相關的參數可參考圖3、4及表1、2。
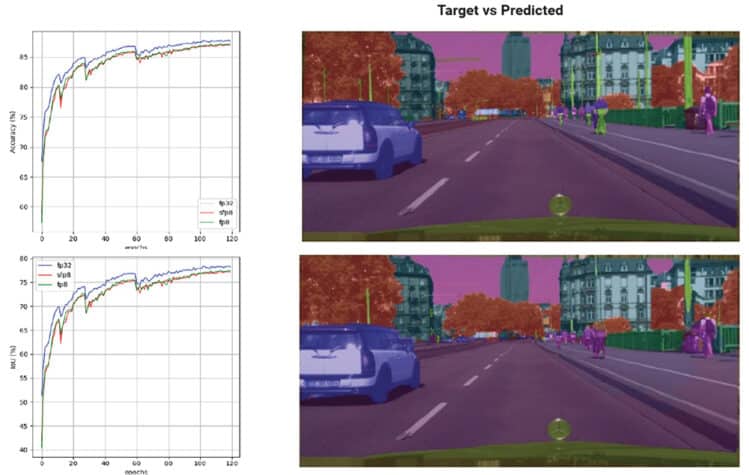
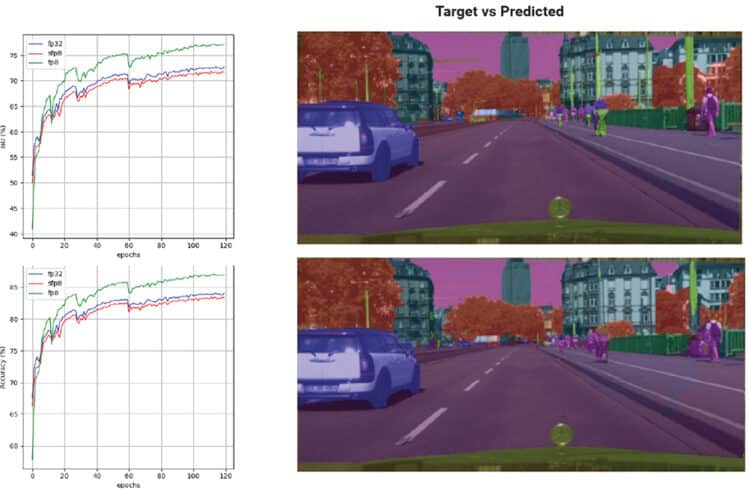
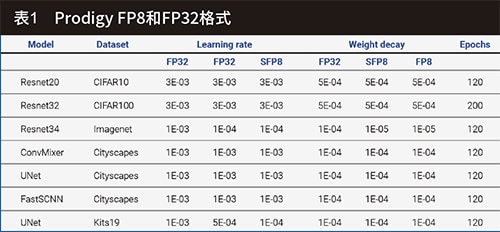
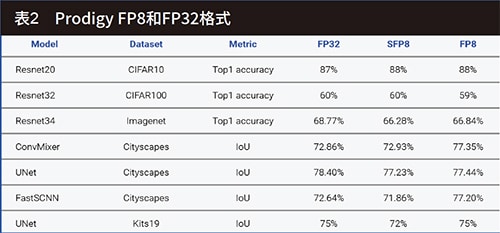
透過稀疏化縮放模型
縮放深度學習模型的另一個重要方法,是剪枝或壓縮神經網路。像是Prodigy具有對區塊結構稀疏(Sparsity)化的原生資源。
與具有不規則記憶體存取,並只提供微小加速的非結構稀疏化不同,區塊結構稀疏化允許卷積被表示為區塊稀疏矩陣乘積,可用於提升運算效能和速度。區塊結構稀疏化在非結構稀疏化的高稀疏率,以及全架構稀疏化的推論速度,之間找到了一個平衡點(表3、4)。


處理器架構解決AI挑戰
新的處理器架構有助於強化AI的效能及功能,此系統可以在不影響模型收斂和準確度的前提下,運算大規模的模型,達到良好的算力及能源使用效益。支援FP8的處理器可以最大化複雜模型的訓練及推論效能,並在關鍵指標如Top 1 Accuracy或IoU上可以保持與原來相差不遠的效能表現。且處理器對區塊結構稀疏化的原生支援,包括用於壓縮的矩陣乘法指令等,有助於深度學習模型進一步提高效能。
(本文由Tachyum提供)