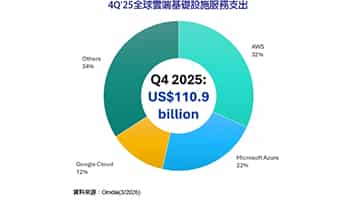
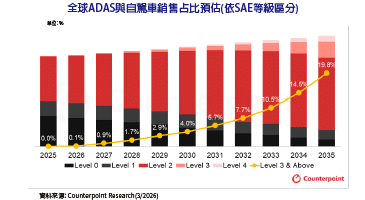
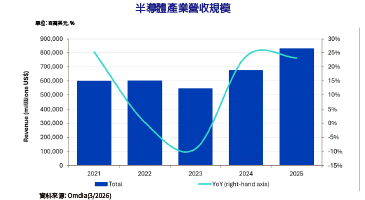
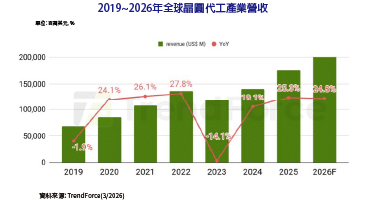
AI引擎程式設計(3) KPN強化AI影像處理效能
本文分成三篇,探討如何基於Kahn處理網路(KPN),定義AI引擎繪圖程式設計模型。上一篇討論到自行調適資料流程程式設計,本篇則提供基於KPN概念,設計AI引擎的範例。該範例設計使用四個AI引擎Kernel(圖12),包含向量加法(VADD)、增加定值(addConstant)、將addConstant複製到輸出(copy_in_out)以及FIR過濾器(fir_32)。
圖12 AI引擎核心
此範例使用兩個版本的FIR過濾器(fir_32),一個是標量程式碼,另一個是向量程式碼。這有助於展現Kernel效能的重要性,以及在設計中使用資料流程程式設計(平行運算)的優勢。
圖13是AI引擎ADF在Vitis分析器工具中的實際應用方案。在該圖中,帶有閃電符號的方框代表Kernel。緩衝區為bufx和bufxd(Ping和Pong緩衝區),例如buf0(Ping)和buf0d(Pong)。輸入和輸出埠分別表示為PLIO_In1、PLIO_In2、PLIO_Out1和PLIO_Out2。接下來將說明如何基於KPN概念來執行設計。
圖13 Vitis分析器工具中的繪圖視圖
第一幀影像
第一組資料開始寫入緩衝區(Ping...
2024 年 02 月 07 日