




提到AI多數人即聯想到「需要龐大記憶體、龐大運算力才能跑」,但Edge AI、TinyML的提出已逐漸讓人改觀。即便如此,所謂的TinyML也多是使用32-bit MCU來跑AI,很難在更低階的MCU上跑。
不過,這個觀感可能又要修正了,GitHub上有一名GiorgosXou帳號者提出NeuralNetwork Library For Microcontrollers函式庫,該函式庫運用各種技法讓AI模型縮小,例如量化(quantization)、SIMD加速、客製的激活函數(activation function)等,讓多種AI模型進一步縮小,包含最基本的前饋神經網路(feedforward network),也包含相對先進的RNN、GRU以及LSTM等神經網路。
將AI模型進一步縮小後,透過實測確實可以在極度侷限的硬體資源環境下跑AI,GiorgosXou用一顆8-bit MCU(ATtiny85,Atmel公司特有的AVR架構MCU,Atmel公司已屬Microchip)來跑AI模型。
ATtiny85 MCU外觀只有8支接腳,內部有8KB Flash程式記憶體、512Bytes SRAM記憶體以及512Bytes EEPROM記憶體。GiorgosXou運用MNIST資料集訓練出一個RNN模型,然後把該模型存入512Bytes空間的EEPROM內,一旦MCU開機後,就把儲存在EEPROM的AI模型資料載入到512Bytes的SRAM內運作。
運用該RNN模型,ATtiny85的8-bit MCU可以識別0~9的手寫阿拉伯數字,實現電腦視覺(Computer Vision, CV)性質的AI識別應用。

技術實現的細節
在這裡各位可能會疑惑:一顆8-bit MCU是如何被輸入影像資料,從而給出0~9的判定結果?答案是把影像轉成一個一個的8-bit(資料從0~255)資料傳入MCU內,總共傳送28 x 28個8-bit矩陣資料,如此形同把一個影像傳入MCU,之後MCU進行AI推論,從而給出0~9的數字判定。
很明顯的,這還是有很大的特技(意味著不太實際)成份,通常電腦視覺的AI識別應用是把一個攝影機的影像傳入晶片後從而給出判定,如何把感測到的影像轉成28 x 28的8-bit資料目前似乎沒有常態且實務的作法。另外,這樣的一次AI推論運算要多久時間?也是考驗是不是合理務實的點。
不過,就概念驗證(Proof of Concept, PoC)而言確實做到了在一顆8-bit MCU內實現電腦視覺AI應用,即便這是個最基礎的手寫數字識別應用,通常是拿來教學或初步體驗AI開發時使用。

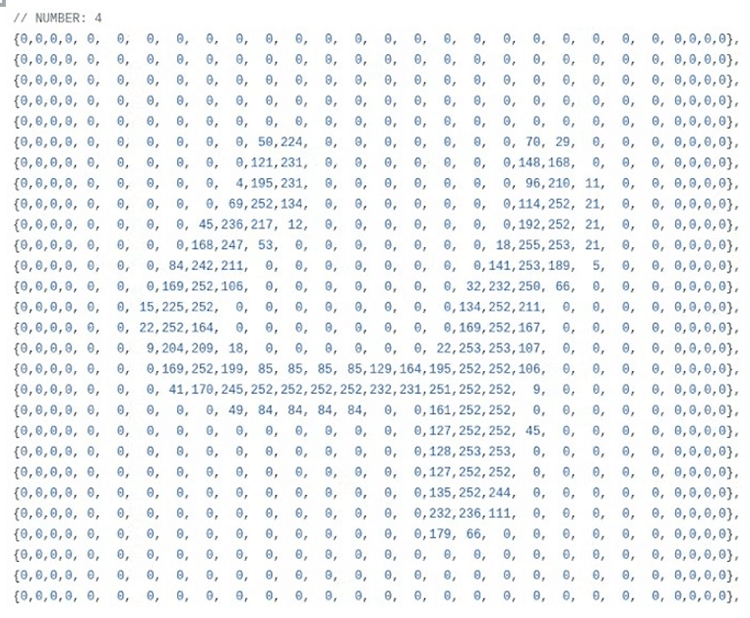
能在ATtiny85上跑有兩個意涵,一是最入門基礎的Arduino開發板都至少會用ATmega328P 8-bit MCU,mega系列明顯比tiny系列硬體資源寬裕,如此意味著所有的Arduino開發板都可以使用這套函式庫。
另一是8-bit MCU、512Bytes如此低的資源也能運作,其他MCU都有比這個寬裕的硬體,也肯定可以輕鬆比照套用,或者是套用到同屬8-bit的MCU架構中,如PIC架構、68HC架構等。
更多實測與細節
除了用極低階的ATtiny MCU外,GiorgosXou其實也已經在一些晶片與開發板上實測過函式庫的可行性,包含最普遍使用的Arduino Uno開發板,或者是樹莓派的Raspberry Pi Pico 2開發板等。
另外,前面提及AI模型可以大幅縮小的原因是用及SIMD加速,這其實在8-bit MCU內幾乎不具備,GiorgosXou所提的SIMD是在ESP-32系列晶片、Raspberry Pi Pico 2(RP2350晶片)等比較新銳的MCU上才能使用。
至於更多的技術細節也包含:GiorgosXou是用TensorFlow進行模型訓練,訓練的範例程式則是用Python程式語言,訓練時使用32位元浮點數精度(或更高的64位元),量化方面則用16位元或8位元整數權重等。
結語
最後其實可以體會到,無論是判別式人工智慧、生成式人工智慧,近年來都因為演算法的精進而大幅降低硬體資源的需求,以更便宜的價格、更精省的電力,卻能得到近似過往的快速結果回應及可接受的準確度,對創客與大眾而言均是福音。
(本文轉載自vMaker台灣自造者,原文連結:https://vmaker.tw/archives/76799)