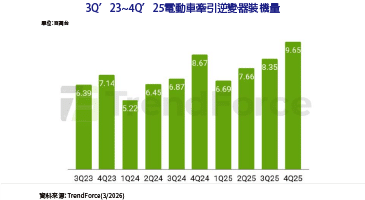
NVIDIA的三維防線與雲端巨頭們的越獄計畫
當全球科技圈還沈浸在Gemini 3的驚人效能時,一個更讓NVIDIA背脊發涼的消息悄然傳出:Anthropic才剛推出的頂級模型,Claude Opus 4.5,竟然也開始大規模採用Google TPU進行訓練,且未來的訓練規模將劍指百萬顆TPU等級,甚至連Meta也對Google遞出橄欖枝。
這是個極具殺傷力的警訊。過去NVIDIA之所以能壟斷市場,是因為CUDA是AI界的「英語」,是唯一的通用語言。Google自研的TPU雖然強大,但一直被視為Google內部的「方言」,出了Google園區就沒人講。但現在,連擁有頂級模型能力的Anthropic都開始講這門方言,#這意味著TPU生態系已經具備了外溢能力。
如果越來越多頂級玩家發現,不繳「黃仁勳稅」也能訓練出世界級模型,NVIDIA的護城河將出現第一道真正的裂痕。
面對「Google效率路線」與「叛軍結盟」的雙重夾擊,NVIDIA的執行長黃仁勳展現了極致的戰略彈性。他不僅祭出了三維防線,更使出了一招令人意想不到的「特洛伊木馬」——開放NVLink授權。
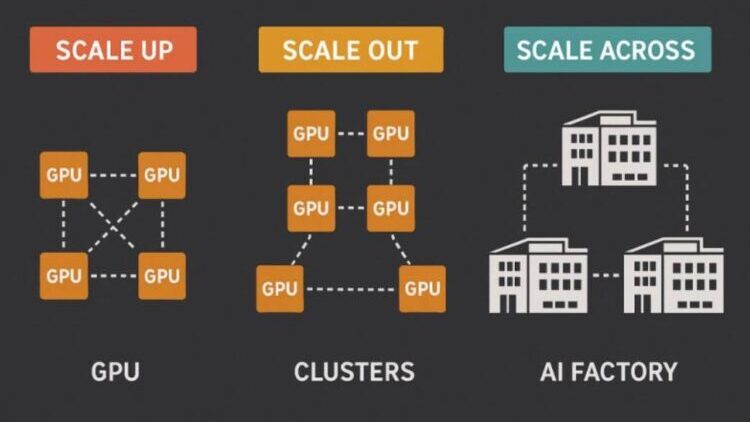
這場算力戰爭,現在演變成了三層同心圓的立體攻防:
第一層:Scale-up的記憶體怪獸與開放陷阱
在GB200...
2025 年 11 月 27 日